主题模型(Topic Model, TM)是一种新型文本内容分析方法,它利用机器学习算法来发现文件集(语料库)中隐藏的主题结构,不仅可以计算生成整个语料库的主题,还可以自动给出每个文件按照主题呈现的内容结构,即抓取每个文件的内容。在信息爆炸的网络时代,学者们需要处理海量文献,通过主题模型用机器阅读的形式,为解决文献增量超出人类精力、理解范围等问题提供了解决途径。并且,新的文献研读方式也将带来新的研究视角,甚至新的研究发现。
人文学者做研究要进行文献研读,研读文献通常采用直接和近距离阅读方式,而TM则引入了新型阅读方式“远距离阅读”(distant reading)和超书架功能。将一个大型文件集的语料库作为计算机的输入数据,只需运行TM算法,就能够自动生成在人文专家看来颇有解释意义的“主题”(topic)。一个主题可以看作是词汇的聚类,无论何时讨论该主题,这些词汇便会共同出现。从概率上说,这些聚类词的共现频率高于不讨论该主题时这些词的共现频率。TM属于语义统计模型中的一种,可称为对语义进行概率统计建模的方法。其中,最简单且应用最广的概率建模技术是布莱(David M. Blei)团队于2003年提出的隐形狄利克雷分布(Latent Dirichlet Allocation, LDA)。近年来,一些人文学者尝试借助主题建模技术辅助文献研读,取得的研究成果已经展现出十分有趣的人文意蕴。
实现大型古典哲学语料库的结构化
依靠人工辨识和分类,要使一个庞大的文件库呈现清晰的结构,往往需要耗费大量人力和时间。而且传统人工方法只能依据文章和著作的名称、著者名、关键词等外部信息,进行外围框架分类和查询,要想深入到文档内容进行海量文档库分类,依靠人工方法难以实现。而TM则能够根据文档内容实现对一个庞大文件库的结构化。这种分类管理的核心在于主题,TM可以呈现出每个文件依据主题(20个、40个直到100个)分布的结构表、结构图。
研究人员以往通常根据关键词搜索查询所需文件,若能够直接看到文件的内容结构,根据研究主题获取相关信息,并能够直接看到文档库中其他文件与此文件主题的关联度,那么,研究人员不但可以便捷、高效地找到所需,而且还能够获得用传统人工方法无法得到的洞见。
TM能够经推理得出文集具有可解释性的隐含结构,并用这种结构标注了每一个文档,这种结构和标注可用于对信息的获取、分类,以及对语料库的开发。这种算法结果可以管理、组织和标记大型文本档案。随着越来越多高质量的数字化文献文本资料库的建立,人们将用新的方式查询和分析文献。
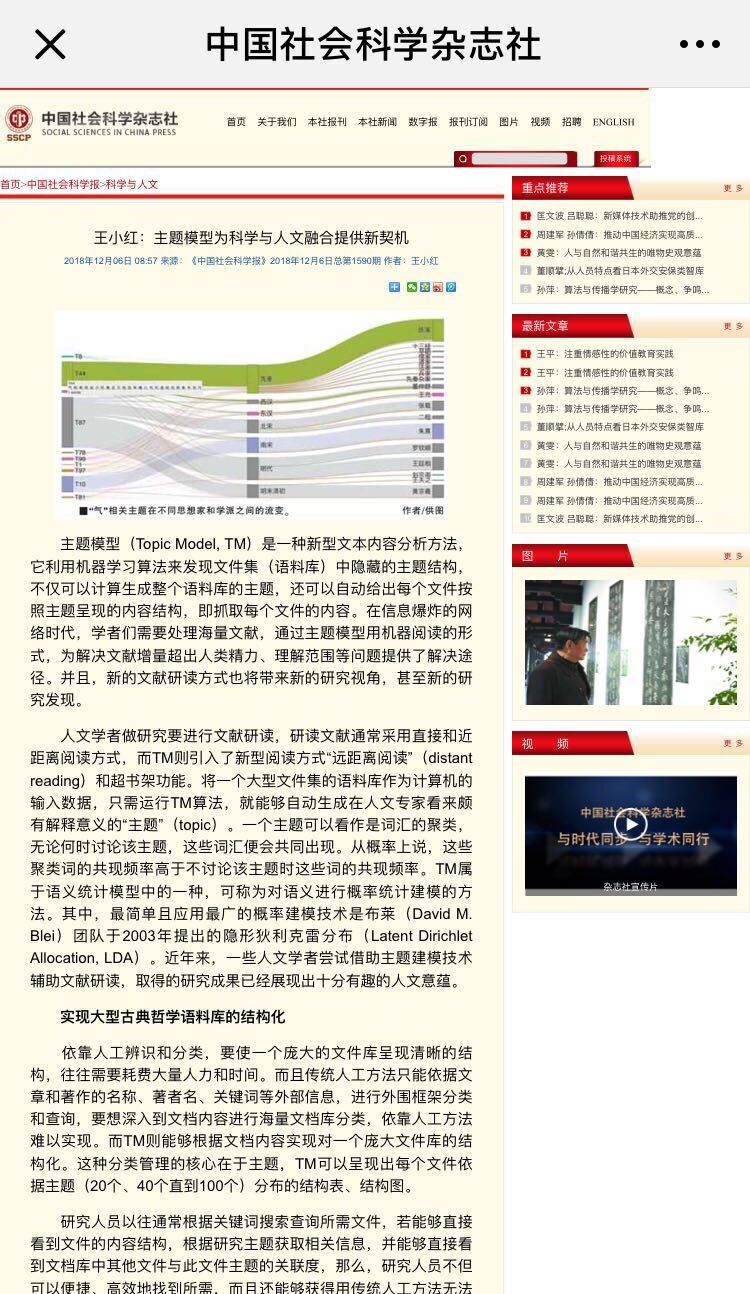
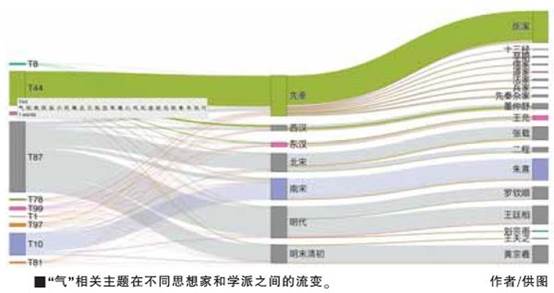
我们和匹兹堡大学计算哲学家艾伦(Colin Allen)的IU(Indiana University)团队合作建立的一个包含近18000个文本的中国古代哲学语料库,通过主题建模分析,呈现出对于中国哲学研究者和学习者颇有解释意义的主题(如图所示)。
为史学研究提供新解读和新证据
在使用主题建模于中国史学研究方面,哈佛大学中国史研究者米勒(Ian M. Miller)对中国清朝社会变乱实况进行了考察。清朝18、19世纪出现的民变四起的社会实况是诸多历史学家的关注点,米勒的工作另辟蹊径,通过分析清朝政府统治者批阅的奏折内容,对这一时期的实录文本材料进行主题建模,基于与暴乱相关主题中共同出现的词群,建构了从各级官员到统治者关于当时社会时局的理解模型。不同历史时期对反映社会实况的词汇缺乏固定定义,历史学家研究史料时不得不通过先验分类定义,而米勒通过主题建模方法,保持了研究的客观性,避免了范畴模糊的词语对理解文意的干扰,并在此基础上探究了清朝出现的几起大型变乱现象的规律性。
加拿大汉学家森舸澜(Edward Slingerland)和美国哲学家尼克斯(Ryan Nichols)合作的团队,近年来致力于结合机器学习研究亚洲文化。2018年,他们用TM的远距离阅读方法对《论语》《孟子》《荀子》的内容进行比较,分别解释了三部论著中相同和不同的主题。他们的结果证实了许多学者采用传统近距离阅读方法得到的结论,即荀子的论著与《论语》在语义内容上存在共性。2017年,他们采用主题建模结合其他算法技术,分析了引起西方汉学界较大争议的问题,即中国传统思想是否以“强”身心整体论为特征。他们建立了一个从西周到宋朝的古籍文本语料库。计算结果显示,荀子及其他中国早期思想家,在提到“心”时往往也会提到心与身体的关系,这表明,比之身体其他器官,心在早期中国思想中具有不同的认知地位。
与文化研究存在高度亲和性
此外,还有一项研究展示了主题建模技术与文化社会学研究的高度亲和性。文化社会学研究者迪马吉奥(Paul DiMaggio)和布莱于2013年合作的一项研究,选取代表性报刊刊登的公共艺术资助方面的新闻报道,使用TM分析其中的演变趋势。美国国家艺术基金(NEA)从1965年设立至今,有过两次骤降,骤降的原因除通货膨胀外,还有复杂的政治、文化、社会等多方面的影响,因此,造成1979—1996年资助持续衰减的原因,至今仍未研究清楚。
围绕NEA争议最激烈的一个时段(1986—1997年),该团队通过收集整理这十年中五家报纸的所有报道,建立了一个近8000个文本、超过300万词语的语料库,使用TM分析识别出最重要的话题,从而框定了政府资助方面的讨论。
TM使文化学中的重要概念如框架、一词多义性、杂语性、意义的关系性具有了可操作性。他们强调,TM进路对文化社会学研究有三大优势:1. TM产生的具有可解释性的主题内容,展现了文化意义上的解释框架。2. TM抓住了语言学家和许多文化社会学者的共同洞见,即意义从关系而非词汇中显现。3. LDA生成的结果呈现出每一篇文章中具有多主题结构,有助于从实证层面检视文化社会学的核心洞见和文本的杂语性。

